Fast approximate string matching with large edit distances in Big Data (2015)

1 million times faster spelling correction for edit distance 3
After my blog post 1000x times faster spelling correction got more than 50.000 views I revisited both algorithm and implementation to see if it could be further improved.
While the basic idea of Symmetric Delete spelling correction algorithm remains unchanged the implementation has been significantly improved to unleash the full potential of the algorithm.
This results in a 10 times faster spelling correction and 5 times faster dictionary generation and 2…7 times less memory consumption in v3.0 compared to v1.6 .
Compared to Peter Norvig’s algorithm it is now 1,000,000 times faster for edit distance=3 and 10,000 times faster for edit distance=2.
In Norvig’s tests 76% of spelling errors had an edit distance 1. 98.9% of spelling errors got covered with edit distance 2. For simple spelling correction of natural language with edit distance 2 the accuracy is good enough and the performance Norvig’s algorithm is sufficient.
The speed of our algorithm enables edit distance 3 for spell checking and thus improves the accuracy by 1%. Beyond the accuracy improvement the speed advantage of our algorithm is useful for automatic spelling correction in large corpora as well as in search engines, where many requests in parallel need to be processed.
Billion times faster approximate string matching for edit distance >4
But the true potential of the algorithm lies in edit distances > 3 and beyond spell checking.
The many orders of magnitude faster algorithm opens up new application fields for approximate string matching and a scaling sufficient for big data and real-time. Our algorithm enables fast approximate string and pattern matching with long strings or feature vectors, huge alphabets, large edit distances, in very large data bases, with many concurrent processes and real time requirements.
Application fields
- Spelling correction in search engines, with many parallel requests
- Automatic Spelling correction in large corpora
- Genome data analysis,
- Matching DNA sequences
- Browser fingerprint analysis
- Realtime Image recognition (search by image, autonomous cars, medicine)
- Face recognition
- Iris recognition
- Speech recognition
- Voice recognition
- Feature recognition
- Fingerprint identification
- Signature Recognition
- Plagiarism detection (in music /in text)
- Optical character recognition
- Audio fingerprinting
- Fraud detection
- Address deduplication
- Misspelled names recognition
- Spectroscopy based chemical and biological material identification
- File revisioning
- Spam detection
- Similarity search,
- Similarity matching
- Approximate string matching,
- Fuzzy string matching,
- Fuzzy string comparison,
- Fuzzy string search,
- Pattern matching,
- Data cleaning
- and many more
Edit distance metrics
While we are using the Damerau-Levenshtein distance for spelling correction for other applications it could be easily exchanged with the Levenshtein distance or similar other edit distances by simply modifying the respective function.
In our algorithm the speed of the edit distance calculation has only a very small influence on the overall lookup speed. That’s why we are using only a basic implementation rather than a more sophisticated variant.
Benchmark
Because of all the applications for approximate string matching beyond spell check we extended the benchmark to lookups with higher edit distances. That’s where the power of the symmetric delete algorithm truly shines and excels other solutions. With previous spell checking algorithms the required time explodes with larger edit distances.
Below are the results of a benchmark of our Symmetric Delete algorithm and Peter Norvig’s algorithm for different edit distances, each with 1000 lookups:

*Correct or unknown word, which is not in the dictionary and there are also no suggestions within an edit distance of
For the benchmark we used the C# implementation of our SymSpell as well as a faithful C# port from Lorenzo Stoakes of Peter Norvig’s algorithm, which has been extended to support edit distance 3. The use of C# implementations for both cases allows to focus solely on the algorithm and should exclude language specific bias.
Dictionary corpus
The English text corpus used to generate the dictionary used in the above benchmarks has a size 6.18 MByte, 1,105,286 terms, 29,157 unique terms, longest term with 18 characters.
The dictionary size and the number of indexed terms have almost no influence on the average lookup time of o(1).
Speed gain
The speed advantage grows exponentially with the edit distance:
- For an edit distance=1 it’s 1 order of magnitude faster,
- for an edit distance=2 it’s 4 orders of magnitude faster,
- for an edit distance=3 it’s 6 orders of magnitude faster.
- for an edit distance=4 it’s 8 orders of magnitude faster.
Computational complexity
Our algorithm is constant time ( O(1) time ), i.e. independent of the dictionary size (but depending on the average term length and maximum edit distance), because our index is based on a Hash Table which has an average search time complexity of O(1).
Precalculation cost
In our algorithm we need auxiliary dictionary entries with precalculated deletes and their suggestions. While the number of the auxiliary entries is significant compared to the 29,157 original entries the dictionary size grows only sub-linear with edit distance: log(ed)
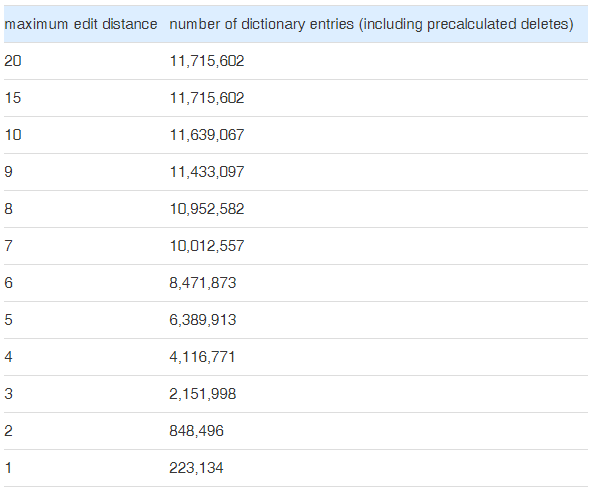
The precalculation costs consist of additional memory usage and creation time for the auxiliary delete entries in the dictionary:
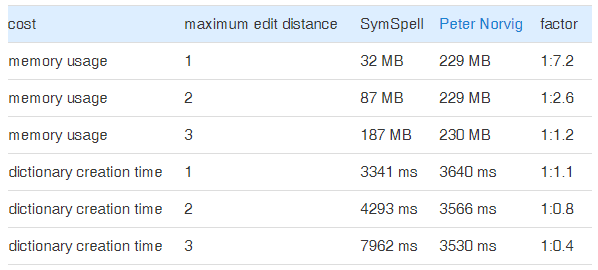
Due to an efficient implementation those costs are negligible for edit distances
- 7 times less memory requirement and a similar dictionary creation time (ed=1).
- 2 times less memory requirement and a similar dictionary creation time (ed=2).
- similar memory requirement and a 2 times higher dictionary creation time (ed=3).
Source code
The C# implementation of our Symmetric Delete Spelling Correction algorithm is released on GitHub as Open Source under the MIT License: https://github.com/wolfgarbe/symspell
Ports
There are ports in C++, Crystal, Go, Java, Javascript, Python, Ruby, Rust, Scala, Swift available.
Comparison to other approaches and common misconceptions
A Trie as standalone spelling correction
Why don’t you use a Trie instead of your algorithm? Tries have a comparable search performance to our approach. But a Trie is a prefix tree, which requires a common prefix. This makes it suitable for autocomplete or search suggestions, but not applicable for spell checking. If your typing error is e.g. in the first letter, than you have no common prefix, hence the Trie will not work for spelling correction.
A Trie as replacement for the hash table
Why don’t you use a Trie for the dictionary instead of the hash table? Of course you could replace the hash table with a Trie (that is just a arbitrary lookup component of O(1) speed for a *single* lookup) at the cost of added code complexity, but without performance gain. A HashTable is slower than a Trie only if there are collisions, which are unlikely in our case. For a maximum edit distance of 2 and an average word length of 5 and 100,000 dictionary entries we need to additionally store (and hash) 1,500,000 deletes. With a 32 bit hash (4,294,967,296 possible distinct hashes) the collision probability seems negligible.
With a good hash function even a similarity of terms (locality) should not lead to increased collisions, if not especially desired e.g. with Locality sensitive hashing.
BK-Trees
Would be BK-Trees an alternative option?
Yes, but BK-Trees have a search time of O(log dictionary_size), whereas our algorithm is constant time ( O(1) time ), i.e. independent of the dictionary size.
Ternary search tree
Why don’t you use a ternary search tree?
The lookup time in a Ternary Search Tree is O(log n), while it is only 0(1) in our solution. Also, while a Ternary Search Tree could be used for the dictionary lookup instead of a hash table, it doesn’t address the spelling error candidate generation. And the tremendous reduction of the number of spelling error candidates to be looked-up in the dictionary is the true innovation of our Symmetric Delete Spelling Correction algorithm.
Precalculation
Does the speed advantage simply comes from precalculation of candidates?
No! The speed is a result of the combination of all three components outlined below:
- Pre-calculation, i.e. the generation of possible spelling error variants (deletes only) and storing them at index time is just the first precondition.
- A fast index access at search time by using a hash table with an average search time complexity of O(1) is the second precondition.
- But only our Symmetric Delete Spelling Correction on top of this allows to bring this O(1) speed to spell checking, because it allows a tremendous reduction of the number of spelling error candidates to be pre-calculated (generated and indexed).
- Applying pre-calculation to Norvig’s approach would not be feasible because pre-calculating all possible delete + transpose + replace + insert candidates of all terms would result in a huge time and space consumption.
Correction vs. Completion
How can I add auto completion similar to Google’s Autocompletion?
There is a difference between correction and suggestion/completion!
Correction: Find the correct word for a word which contains errors. Missing letters/errors can be on start/middle/end of the word. We can find only words equal/below the maximum edit distance, as the computational complexity is dependent from the edit distance.
Suggestion/completion: Find the complete word for an already typed substring (prefix!). Missing letters can be only at the end of the word. We can find words/word combinations of any length, as the computational complexity is independent from edit distance and word length.
The code above implements only correction, but not suggestion/completion!
It still finds suggestions/completions equal/below the maximum edit distance, i.e. it starts to show words only if there are <= 2 letters missing (for maximum edit distance=2). Nevertheless the code can be extended to handle both correction and suggestion/completion. During the process of dictionary creation you have to add also all substrings (prefixes only!) of a word to the dictionary, when you are adding a new word to the dictionary. All substring entries of a specific term then have to contain a link to the complete term. Alternatively, for suggestion/completion you could use a completely different algorithm/structure like a Trie, which inherently lists all complete words for a given prefix.
Originally published at seekstorm.com on March 24, 2015.
